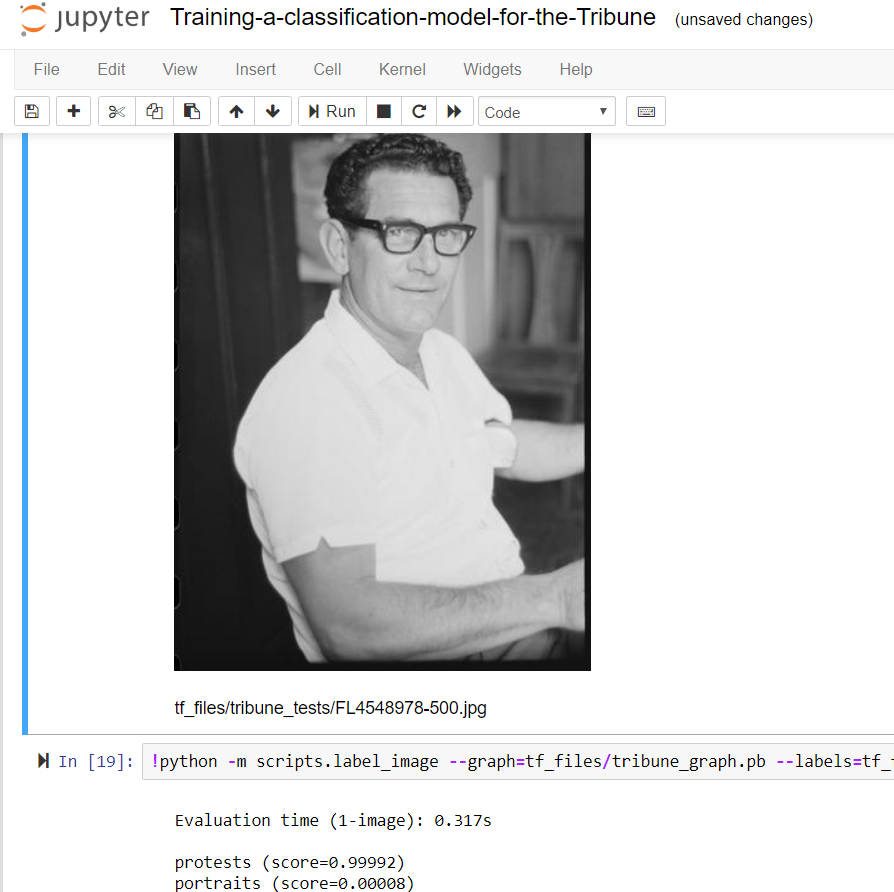
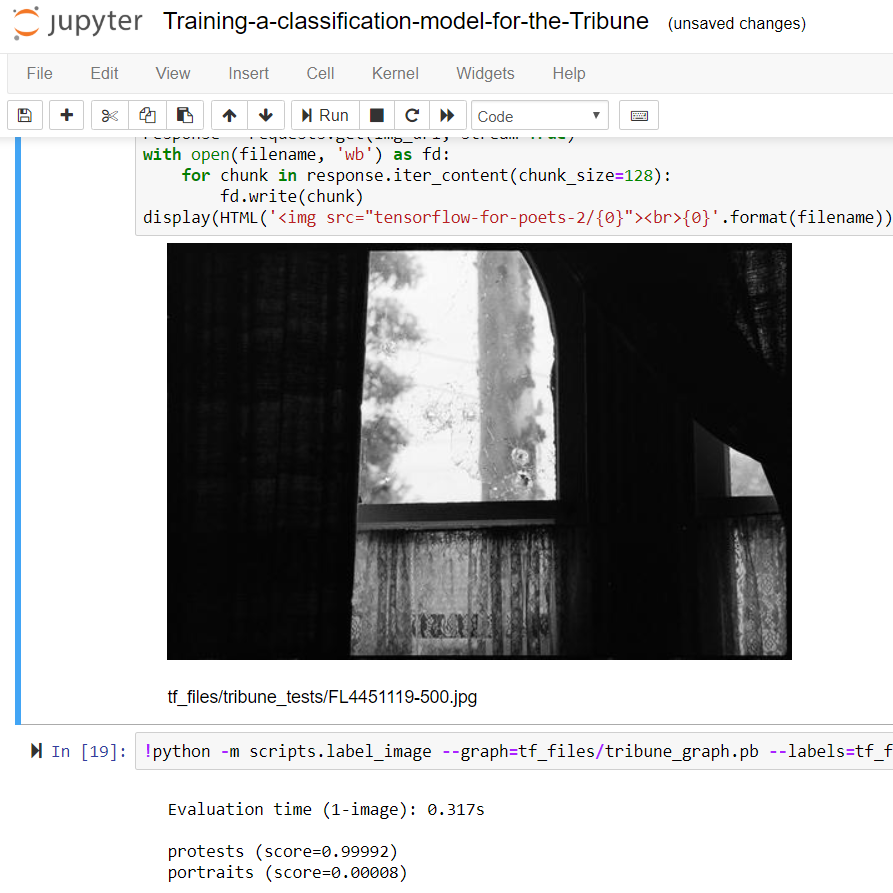
The final stage of the Machine Tagging and Computer Vision group’s investigations looked at the potential of implementing basic facial detection technology (in this case, using OpenCV) to the Tribune collection in an effort to determine alternative methods for users to discover and navigate this extensive resource. While our group was not responsible for the technical aspects of this experiment, we were involved in interpreting the resulting data and attempting to identify where there might be advantages to utilising this approach.

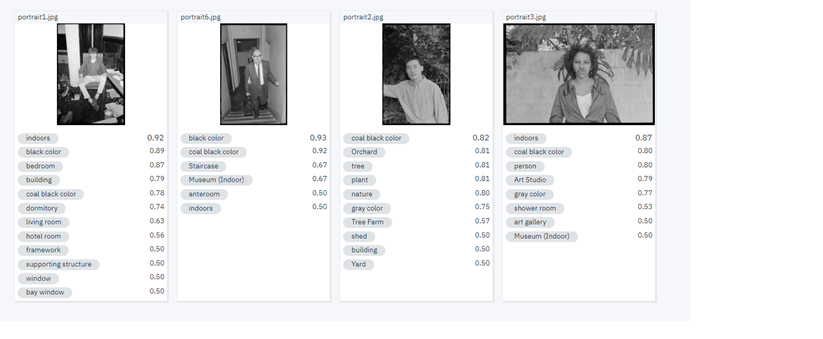
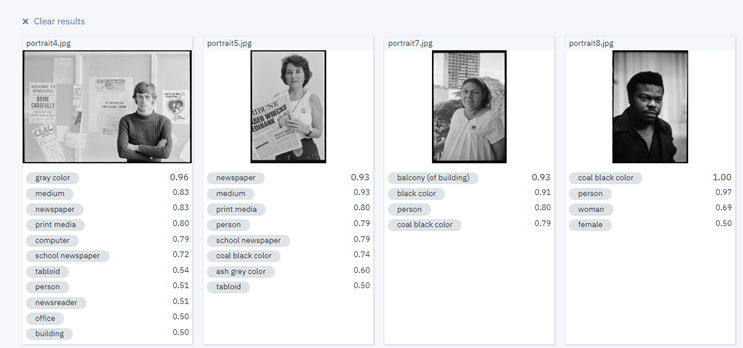
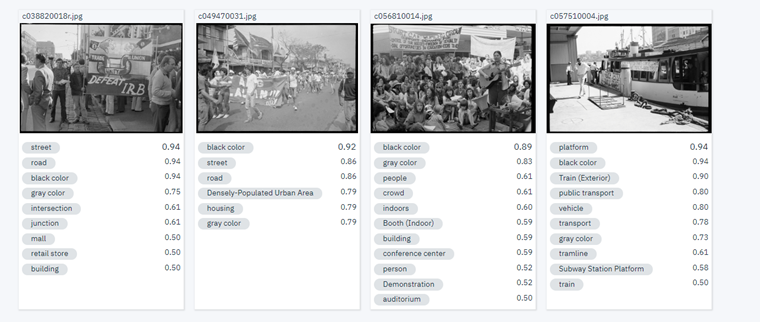
While initially considering the possibilities of this option limited, we soon discovered that that even simply finding faces in the Tribune collection could prove extremely valuable. This approach had the potential to not only distinguish the photographs with people from those without, but also possibly reveal a bit about the nature of a particular image by the number of faces it contains.

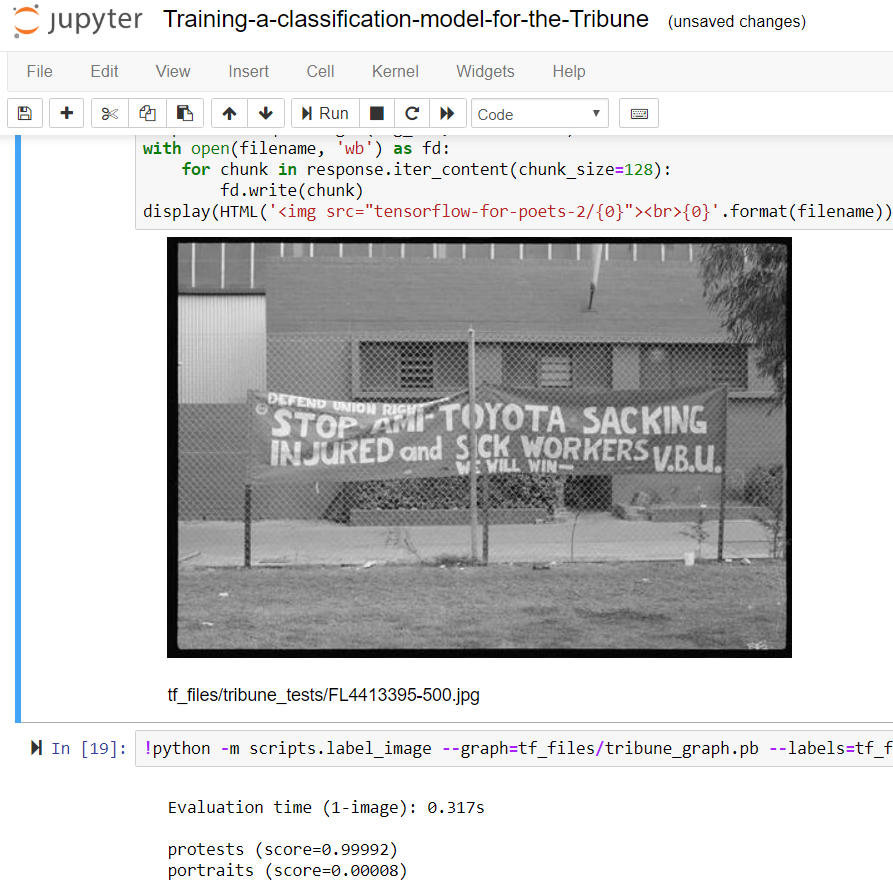
Although not guaranteed to pick up on every single face, and with varying accuracy across the many different images, the ability of facial detection to return an approximate number could prove useful in determining the likelihood of a photograph being of an individual or a crowd. Such information could be very useful in this particular case, and provide another path for people searching the Tribune images. The option to only show those with, for instance, more than 10 or 20 faces could direct users to photographs of protests or meetings – and there may well be other ways of using the resulting data to assist people through the collection.
Exploring the data generated from this experiment gives us the opportunity to see an overview of faces in the collection, revealing how many images in total were reported to contain faces, as well as the average number of faces per image and a chart demonstrating face frequency across the 60,000 Tribune photographs. Additionally, listing those images with a face count that exceeds 100, making it possible to zoom in on them to see exactly what they’re about.
Of course, it’s important to consider that the ‘face’ being identified may not always be a face…
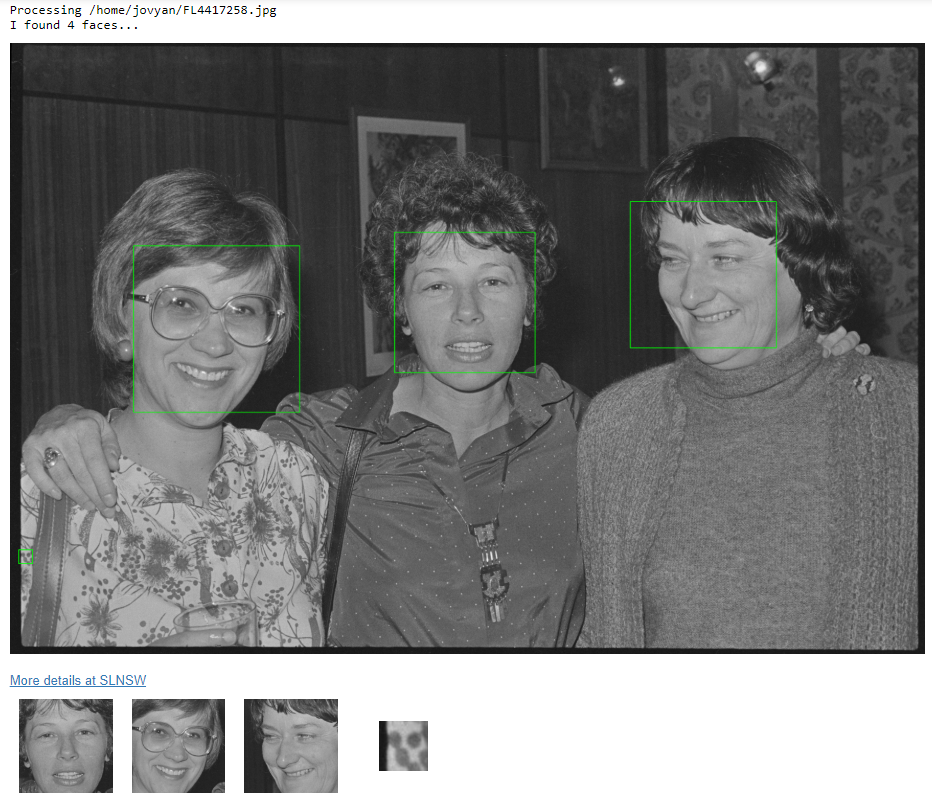
In this case, a group portrait of 3 individuals supposedly contains 4 faces, with the computer picking up on something that merely resembles a face in a pattern (something we noticed happening quite frequently). False positives such as these are inevitable and can certainly be filtered out in order to ensure more accurate results, although it’s actually quite interesting to see what mistakes are being made, and consider how the facial detection technology is making its decisions.
In all, 230,677 ‘faces’ were detected, and this experiment demonstrated a few creative ways of using them – by extracting them from their context and making them the focus. Some interesting things resulted from focusing on faces of the Tribune collection. In this case, the cropped versions of each identified face became part of a single, enormous image – which can be viewed in detail here.

Another approach involves randomly selecting a photograph from the Tribune collection which has been determined to contain more than 20 faces, and from it, generating a different version of the detected faces in isolation. It’s then capable of a demonstrating a transition between the two images.

Faces have the power to really draw people in – initially isolating them from their context, its then possible to add the context back in order to see what’s actually going on in a photograph. From what we’ve seen, these approaches could prove to be an extremely effective and engaging way of presenting the Tribune collection.
As noted with our previous experiment, it’s possible to see the potential of basic facial detection even in its unpolished, preliminary form. Even such a simple process as this may provide opportunities for extracting useful metadata, and so could prove an effective means of enriching the collection, as well as opening it up for people to find and experience this resource based solely on the properties of the images themselves.
(If you’re interested, the facial detection notebook for this experiment can be found and tested out here).