The Machine Tagging and Computer Vision group started out by investigating the effectiveness of some available demo versions of automated tagging services, which meant relying on the default models that these services had been trained on and seeing whether or not they proved to be useful. We attempted to put together a fairly comprehensive test set of images from the State Library of New South Wales’ Tribune collection to run through four programs, one of which being Imagga, and note the results.
The Imagga API is described as a set of image understanding and analysis technologies available as a web service, allowing users to automate the process of analysing, organising and searching through large collections of unstructured images, which is an issue we’re trying to address as part of our class project.
Imagga provides reasonably thorough and easy to use demos which are accessible to the public without any sign-up requirements. They include options regarding the automated tagging, categorisation, colour extraction, cropping and content moderation of image collections. It should be noted that Imagga is lacking the facial detection component included in some of the other services we tested. For the purposes of this exercise, only the automated-tagging service was trialed.
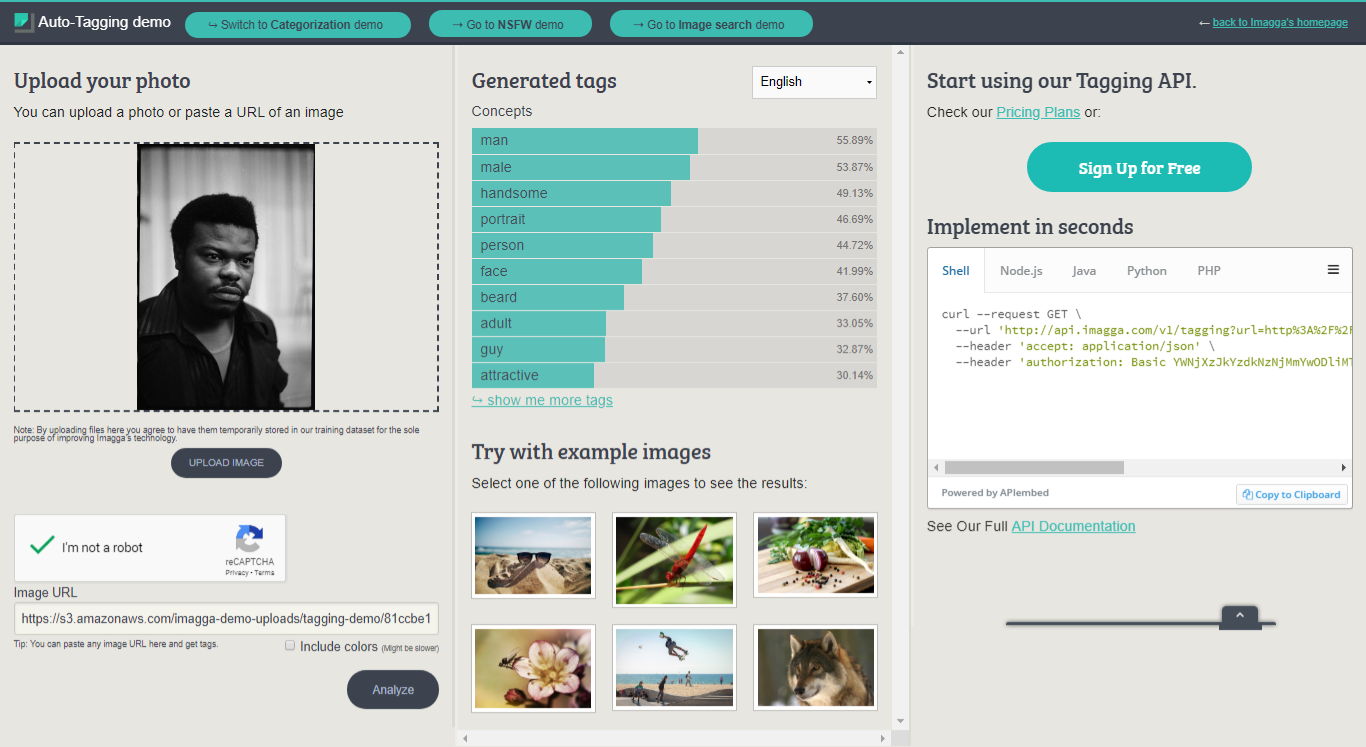
Returned is a list of many automatically suggested tags (the exact number varies depending on the image) with a confidence percentage assigned to each. The tags generated may be an object, colour, concept, and so on. The results can be viewed in full here: Machine Tagging and Computer Vision – Imagga Results.
While the huge amount of tags may seem promising at first, a closer look at the suggestions reveals that there is a lot of repetition and conflict (both ‘city’ and ‘rural’,’ transportation’ and ‘transport’, ‘child’ and ‘adult’, ‘elderly’ and ‘old-timer’). Although Imagga doesn’t return as many of the more redundant and predictable tags that some of the other services generated, it’s going to the other extreme with some very obscure and specific results, which is interesting. Things such as ‘planetarium’, ‘shower cap’, ‘chemical’, ‘shoe shop’ for perfectly standard images of meetings. Protest images resulted in concepts such as ‘jigsaw puzzle’, ‘shopping cart’, ‘cobweb’ and ‘earthenware’ – often receiving a high confidence percentage. Ultimately, we can’t really know what is being ‘seen’ as the computer analyses the images, though I found myself wanting to know.
In many cases the results were wildly inaccurate, but Imagga seems capable to an extent (although the confidence percentages weren’t very useful). Although still not perfect, I’d say it’s more suited to portraits than any other category – but suggesting tags such as ‘attractive’, ‘sexy’, etc. to describe images of people could be considered slightly inappropriate, and it would do this in almost every case.
Even if these services are able to achieve accuracy, the main question to ask is whether or not the results would prove useful. Ultimately, we’re looking to see if any of the tags being generated could provide those searching the Tribune collection with some useful access points from which to do so. There’s a lot to pick over in this case, and there may well be useful tags within those supplied, but on the surface, things don’t look too hopeful. However, as Imagga explains – while it’s possible for these out-of-the-box models to suggest thousands of predefined tags, the potential of auto-tagging technology lies in its ability to be trained. Although, in order to take full advantage of Imagga’s services, including their customisable machine learning technologies, it is necessary to sign up and select an appropriate subscription plan.